Introducción
Derivado de sus atribuciones y funciones, las diferentes áreas universitarias recopilan, generan, almacenan, transmiten y aseguran diariamente un gran número de datos recurrentes organizados a partir de diferentes fuentes, plataformas y servicios. La calidad de los datos es primordial para la planeación, seguimiento y ejecución de sus actividades en tanto que facilita la toma informada de decisiones a nivel operativo, táctico y estratégico.
La calidad de datos se refiere a los procesos y técnicas orientadas a mejorar la eficacia, integridad, auditabilidad, oportunidad y confiabilidad de los datos existentes en relación al grado en el que los datos satisfacen las necesidades universitarias.
Administrar y mejorar la calidad de los datos impacta directamente en el uso de los mismos por personas y sistemas en tanto que fortalece su coherencia semántica y su consistencia sintáctica, además de optimizar la utilidad de la información. La calidad contribuye a agilizar los procesos académicos y administrativos, facilitar la gestión, mejorar las operaciones e impulsar la cooperación y el intercambio de información entre las áreas universitarias mediante el aprovechamiento de la infraestructura tecnológica.
Por el contrario, la mala calidad de los datos ocasiona efectos indeseados en la organización por uso de datos incorrectos, produce la mala planificación, fomenta la creación de silos de información, el diseño de procesos incoherentes, la elaboración de documentación incompleta, la inaplicabilidad de normas y genera fallas en la formación de un gobierno de datos (DAMA, 2017); además puede generar un análisis con resultados erróneos que conduzcan a decisiones inadecuadas e, incluso, a incumplimientos normativos.
Propósito
Este documento tiene la finalidad de servir como guía a los responsables TIC de la UNAM y, en general, al personal que interviene en la generación, actualización, recopilación, compartición y almacenamiento de la información universitaria, respecto a la implementación de buenas prácticas sobre la calidad de los datos en términos del fortalecimiento de su confiabilidad, disponibilidad y seguridad.
Glosario
Datos. Son representaciones de hechos concretos sobre el mundo (DAMA, 2017). Por ejemplo: Número de cuenta, fecha de nacimiento, nombre y apellidos de un alumno. Datos oscuros. (Gartner, s/f) define a los datos oscuros o dark data como los activos de información que las organizaciones recopilan, procesan y almacenan durante las actividades comerciales regulares, pero generalmente no los utilizan para otros fines (por ejemplo: análisis, relaciones comerciales y monetización directa). Las organizaciones a menudo almacenan estos datos solo con propósitos de cumplimiento. Almacenar y proteger los datos habitualmente genera más gastos y, a veces, genera más riesgos que valor.
Datos sucios. Datos incompletos, erróneos, inexactos o que no cumplen con cualquiera de las características de calidad asignadas.
ETL - Extraer, transformar y cargar (Extract, Transform and Load). Es el proceso que permite a las organizaciones mover datos desde múltiples fuentes, reformatearlos, depurarlos y cargarlos en una nueva base de datos, data mart o data warehouse, para su análisis.
Indicadores de actividad. Datos cualitativos o cuantitativos (magnitud) considerados como signo o indicio de la presencia de una condición, con características o propiedades definidas. Para que un dato o estadístico pueda ser considerado como un indicador, debe contar con un punto de referencia contra el cual pueda compararse.
Indicadores de desempeño. Razones, proporciones, porcentajes, tasas u otros valores cuantitativos que permiten a los tomadores de decisiones evaluar el desempeño en alguna actividad sustantiva o estratégica. También se utilizan en análisis comparativos o históricos posteriores.
Limpieza de datos (Data cleaning). Se refiere a la depuración de los datos. Consiste en la detección, validación, corrección, sustitución o eliminación de datos incorrectos, inexactos, incompletos, inconsistentes, falsos o corruptos dentro de una base de datos o conjunto de datos.
Métricas. Medidas de calidad en la que un dato posee un atributo dado: exactitud, completitud, integridad, relevancia, entre otros.
Perfilado. Conjunto de técnicas de identificación de datos erróneos, nulos, incompletos, sin integridad referencial, no ajustados al formato requerido o a patrones de información de negocio, tendencias, medias o desviaciones estándares, entre otros.
Características de calidad de los datos
La norma ISO 25012:2008 define la calidad de datos como el grado en el que los datos satisfacen las necesidades de los usuarios. También establece un modelo de calidad para los datos conservados en un formato estructurado, a fin de ser utilizados por un sistema informático. Adicionalmente, la norma define 15 características de calidad de los datos, cada una de las cuales refleja un aspecto específico. Dichas características se agrupan en tres dimensiones:
- Dependientes. La calidad está subordinada al sistema que hace uso de los datos.
- Inherentes. Tienen el potencial intrínseco para satisfacer las necesidades establecidas cuando los datos son utilizados bajo condiciones específicas, es decir, “se refiere al dato en sí y a la correspondencia del mismo con la información del mundo real” (Yanes, 2019).
- Dependientes e inherentes (compartidas). Son características comunes a ambos enfoques.
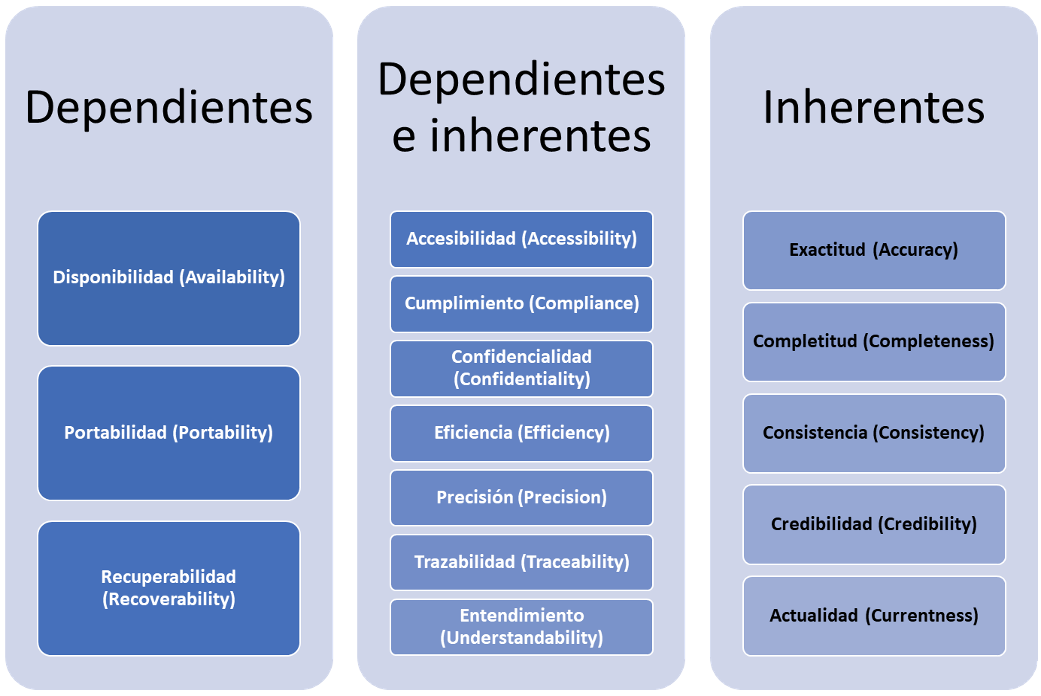
La descripción de cada atributo se encuentra en el Anexo 1: Descripción de los atributos de calidad de los datos.
Aplicando lo expuesto al contexto de la UNAM, las siguientes descripciones pueden distinguirse como representativas de la calidad de los datos universitarios:
- Disponibilidad
- Accesibilidad: Las interfaces de acceso a los datos facilitan su divulgación para ser consultados de manera sencilla y en condiciones de igualdad por diferentes tipos de perfiles.
- Oportunidad: Los datos se actualizan regularmente y el intervalo de tiempo entre su recopilación, procesamiento y liberación cumple con los requisitos necesarios para que mantengan su utilidad.
- Vigencia: Indica el tiempo que el sujeto obligado de datos personales puede conservar la información en sus sistemas antes de eliminarla mediante un protocolo seguro.
- Usabilidad
- Credibilidad: Para que un dato pueda ser utilizado en un contexto específico debe provenir de una fuente especializada, ser auditado regularmente y cumplir con estándares generales, entre los que se incluye la posibilidad de verificar la exactitud de su contenido. En función de ello, los datos se clasifican como conocidos o aceptables.
- Confiabilidad
- Exactitud: Los datos son precisos y su representación refleja el estado real de la información de origen, sin generar ambigüedades.
- Consistencia: Los datos coinciden en sus conceptos, dominios y formatos después de ser procesados, además son verificables durante un tiempo determinado.
- Integridad: Los datos tienen un formato claro que cumple con los criterios de integridad estructural y de contenido.
- Completitud: Nivel de certeza sobre la ausencia de deficiencias en los componentes del sistema o de la base que pudieran afectar el uso, precisión e integridad de los datos.
- Pertinencia
- Convivencia: Los datos recogidos presentan cierta relación o coincidencia que permite ubicarlos dentro del campo específico de conocimiento requerido por los usuarios.
- Pertinencia de uso: Establecimiento de un propósito claro y transparente para el uso de los datos.
- Calidad de presentación
- Legibilidad: Los datos son claros, comprensibles, satisfacen las necesidades del usuario y su descripción, clasificación y contenido son fáciles de entender (Jacintogr, 2020).
Por otra parte, los problemas de calidad en los datos se materializan habitualmente en tres contextos diferentes de amenaza:
- Cuando existen anomalías en una única fuente de datos.
- Cuando datos no estructurados son migrados a una fuente de datos estructurada.
- Cuando se realizan procesos de integración en una única fuente datos de información proveniente de diversas fuentes.
Recomendaciones
Documentación de los requisitos de calidad de datos
Es conveniente describir, como mínimo, las características de los datos que sean más relevantes para revisar su calidad, incluso establecer métricas “a través de las cuales se define la forma en la que cada dimensión es medida” (Yanes, 2019). Para ello se deben tomar en cuenta los requisitos identificados del usuario (Anexo 2. Métricas del estándar ISO/IEC 25024:2015 Systems and software engineering — Systems and software Quality Requirements and Evaluation (SQuaRE) — Measurement of data quality).
Por ejemplo:
|
Característica |
Descripción |
Criterio de evaluación |
|
Completitud |
Nombre: Dato obligatorio Primer apellido: Dato obligatorio Segundo apellido: Dato opcional Número de cuenta: Dato obligatorio |
Se evalúa cada uno de los datos obligatorios. Si el dato presenta un valor, obtiene un punto; en caso contrario, su calificación es cero. |
|
Confidencialidad |
Número de cuenta, nombre, primer y segundo apellido reciben tratamiento de datos personales. |
Si el dato evaluado es tratado como dato personal en el sistema, el dato obtiene un punto; en caso contrario, su calificación es cero. |
|
Exactitud - Semántica |
Número de cuenta: El número de cuenta de los alumnos está compuesto por nueve dígitos a partir de la generación 2000. Por ejemplo: 12345678-9
El número de cuenta de las generaciones 1999 y anteriores está conformado por ocho dígitos. Por ejemplo: 1234567-8 |
Si el número de cuenta está compuesto por 9 dígitos ó, en su caso, por 8 dígitos si corresponde a la generación 1999 o a una anterior, el dato obtiene un punto, en caso contrario su calificación es cero. |
|
Exactitud - Sintáctica |
El número de cuenta está compuesto por valores numéricos, sin guion como separador del dígito verificador. |
Si el número de cuenta presenta únicamente valores numéricos, obtiene un punto; de lo contrario, su calificación es cero. |
|
Precisión |
Entidad federativa de nacimiento, de acuerdo con el catálogo de INEGI. |
Si la clave de la entidad federativa corresponde al catálogo de INEGI, obtiene un punto; de lo contrario, su valoración es cero. |
En la definición de las métricas se pueden agrupar los criterios de evaluación, por ejemplo:
|
Métrica: Completitud. Propósito: Verificar que los requisitos de los usuarios se ven reflejados en los datos, asegurando que no falten ni haya datos adicionales. Método de aplicación: Contabilizar el puntaje obtenido por el dato en los criterios de evaluación de completitud para compararlo con el puntaje total que podría ser obtenido. Fórmula: Puntaje obtenido por el registro / puntaje total esperado. |
Información estadística universitaria
La calidad de los datos mantiene una relación cercana con la información estadística generada en la Universidad, en tanto que -a partir de la calidad de los datos- la información generada es confiable, comparable y oportuna para la planeación, el seguimiento, la toma de decisiones, la transparencia y la rendición de cuentas. Los datos que se obtienen de las fuentes primarias son procesados y organizados con la finalidad de dotarlos de valor estadístico.
La información recabada se valida contra el comportamiento histórico de las variables de interés, así como con la propia fuente primaria en el caso de haber recibido un archivo básico que requiera de un proceso de agregación y presentación adicional.
Cualquier variación en la aplicación de los criterios estadísticos y/o fechas de corte puede provocar que la estadística recabada y procesada no sea comparable con los ejercicios anteriores. Todos los productos resultantes tienen origen en la base de datos construida con el acopio sistemático de información estadística.
Aun cuando los atributos homogéneos y consistentes de la información favorecen su comparabilidad en el tiempo, un mismo concepto con diferentes criterios estadísticos y fechas de corte que responden a distintos fines son igualmente válidos.
Un dato estadístico puede ser diferente cuando se le considera con atributos distintos. Por ejemplo: los períodos fiscales no son lo mismo que los ciclos escolares; los valores de algunos indicadores estadísticos pueden ser diferentes, según el criterio con el cual se reportan. Del mismo modo, un indicador puede variar según la fecha de corte; por ejemplo, es probable que el número de alumnos inscritos sea distinto durante el periodo inicial de inscripciones al obtenido después del proceso de altas, bajas y cambios o justo antes de la emisión de las actas de examen.
Monitoreo de la calidad de los datos
Para asegurar la correcta calidad de los datos es necesario gestionarla de forma continua, definiendo con claridad los niveles de aceptación para cada dato y puntos de control.
Llevar a cabo revisiones periódicas de los datos mediante análisis situacionales o de diagnóstico contribuye a la identificación de problemáticas en la calidad de los datos, tales como: ausencia de valores, valores erróneos o imprecisos, errores ortográficos, violación a las restricciones de unicidad, integridad referencial o verificación, violación de los dominios de datos, errores de dependencias funcionales, duplicidad innecesaria de la información, datos duplicados incorrectos, errores de sintaxis, inconsistencias en las unidades de medida, heterogeneidad en la captura (por ejemplo, entre mayúsculas y minúsculas), inexistencia de catálogos o catálogos no definidos apropiadamente, entre otras. Es recomendable que las citadas revisiones y análisis sean efectuadas por el dueño de la información, acompañado del administrador de la base de datos.
Así mismo, en una base de datos se pueden desarrollar diferentes tipos de análisis de la calidad de los datos, por ejemplo: a nivel de columna, de tabla, de tablas cruzadas para evaluar la integridad referencial, así como también reglas de datos. Tales procedimientos facilitarán la identificación de las causas raíz de los problemas de calidad encontrados. Una vez detectadas e identificadas las anomalías, podrán tomarse las medidas correctivas apropiadas a fin de evitar que los procesos de toma de decisiones estén soportados sobre información incorrecta.
Por lo regular, la tarea de medir la calidad de los datos en el entorno de bases de datos implica utilizar herramientas y métodos especializados como la valoración del nivel de madurez en la calidad de los datos.
Diseño de bases de datos relacionales
El diseño de las bases de datos relacionales puede ayudar a fortalecer la calidad de los datos, siempre y cuando represente y cubra en su totalidad las necesidades de los usuarios que hayan sido identificadas para cumplir con la característica de completitud.
Cuando se diseña el modelo de datos por primera vez, o se revisa un modelo existente, es esencial comprender la naturaleza de los datos a tratar. Esto implica asegurar que el diagrama cumpla con lo siguiente:
- Estar completo y representar todos los requerimientos que se necesita modelar, por lo que es conveniente detallar el diagrama para obtener el modelo de datos físico1.
- Estar construido de acuerdo con el lenguaje utilizado, con estructuras adecuadas a las necesidades que se están modelando.
- Contener sólo las entidades necesarias y reducir al mínimo la repetición de datos, ser fácil de entender y representar la realidad que intenta modelar.
- Ser legible, es decir, sin superposiciones de objetos, ni cruces de línea que dificulten su comprensión.
- Se debe establecer una convención de nomenclatura para el nombrado de las entidades, campos, vistas y procedimientos que represente la información, que tienen o manejan. Para ello es preciso considerar:
- El uso de denominaciones descriptivas, en sustitución de acrónimos difíciles de entender y fáciles de olvidar.
- Evitar campos del mismo nombre, pero con diferentes tipos o significados.
- Evitar redundancias en la denominación de los campos: “Nombre del artículo” y “Precio del artículo” puede sustituirse por “Nombre” y “Precio”.
- No utilizar palabras reservadas para el motor de base de datos.
- Emplear la regla de la clave primaria simple (autogenerado único entero), asignándole el nombre o prefijo “id” en cada tabla (Martínez, 2017) cuando sea adecuado para el modelo.
- Cada base de datos debe normalizarse, al menos, a la tercera forma normal2.
- Todas las entidades deben tener una llave primaria.
- Los nombres de las entidades y atributos deben utilizar un estándar definido por el área responsable de la información o, en caso de no existir, por el equipo de trabajo y validado con dicha área.
- Los nombres de las entidades deben ser únicos.
- Los nombres de los atributos deben ser únicos dentro de las entidades.
- Utilizar restricciones de llave foránea cuando sean necesarias.
- Verificar que los tipos de datos sean adecuados a los valores que va a contener el atributo. Ejemplo de una práctica incorrecta: diseñar un atributo para almacenar fechas con un tipo de dato cadena puede ocasionar el almacenaje de datos incorrectos o con formatos heterogéneos.
- Evitar, en la medida de lo posible, la captura libre de información cuando ésta pueda proceder de catálogos. Por ejemplo: los códigos postales se pueden obtener de un catálogo y, a partir de ellos, derivar la colonia, el municipio y el estado. Otro caso es el nombre de las áreas universitarias, donde es preferible seleccionar los valores y usar los catálogos con nombres y claves que ayuden a la interoperabilidad entre los sistemas.
- Revisar que los tipos de datos usados sean homogéneos: por ejemplo, para el primer apellido de alumnos, trabajadores u otras personas se podría emplear un tipo de datos varchar(50) en sus respectivas entidades, en lugar de diferentes especificaciones como varchar(50) para alumnos y varchar(40) para trabajadores.
- La redundancia de los datos en tablas y campos debe utilizarse sólo en casos específicos y será documentada con claridad para ser contemplada en futuros desarrollos.
- Considerar la creación de índices en todas las columnas diferentes a la clave principal que se utilizan en la cláusula WHERE de manera recurrente para consultar la tabla, ordenando las columnas de las más a las menos utilizadas. Asimismo, se recomienda usar el mismo orden al crear el índice y al consultar la base de datos, de lo contrario pudiera resultar contraproducente al tiempo de respuesta al aumentarlo o mantenerlo igual en lugar de disminuirlo.
Debido a que no todas las bases de datos existentes en la Universidad son relacionales, sin importar la tecnología empleada debe considerarse al menos:
- Utilizar una herramienta de modelado y documentación correspondiente a la tecnología de almacenamiento y explotación de datos que utilice: base de grafos, bases de datos orientadas a objetos, documentos, textos, por mencionar algunos.
- Complementar el diseño con otro tipo de diagramas, como el modelado de Unified Modeling Language (UML), sobre todo cuando no se utiliza una base de datos relacional3 como MongoDB4.
- El diseño debe ser flexible, es decir, con “la capacidad de poder tolerar cambios en los requisitos y adaptarse a nuevas necesidades de los usuarios” (González, 2013).
- Desarrollar el diseño conforme a las reglas, estándares y convenciones establecidas por el área universitaria.
- Documentar el diseño y asegurar que los documentos disponibles son entendibles y suficientes para comprender el modelo.
- Al modelar datos es importante recordar que la información contenida en ellos es la que da sentido a las aplicaciones; no al contrario. Así mismo, el propósito de la documentación es comunicar el diseño y hacerlo comprensible a otras personas en el futuro. Esto es útil si hay una rotación de personal.
Sistemas
En los sistemas, la calidad de los datos dependerá del grado en el que reflejen la información a partir de su exactitud, consistencia, oportunidad e integridad, desde su captura hasta la generación de informes.
Los datos con baja calidad afectan el desempeño de los sistemas de información en las organizaciones. De igual forma, si los datos recibidos por el sistema se almacenan en una base de datos, antes de ser validados, pueden generar errores que se traduzcan en una inversión de tiempo y recursos para la detección y corrección de los datos erróneos.
Es por ello que el diseño y validaciones de los sistemas tienen un alto impacto en la calidad de los datos, debido a que contribuyen (mediante la implementación de controles) a mantener la consistencia de los datos, cumplir las reglas de negocio, verificar que los datos obligatorios sean ingresados y emplear prácticas de programación segura, entre otros aspectos. Es por esto que en la definición de los requerimientos funcionales y no funcionales se sugiere incluir y documentar aquellos que contribuyen a mejorar la calidad de los datos.
El fortalecimiento de los sistemas, junto con la capacitación de los usuarios que capturan la información, contribuye a mitigar los riesgos de tener información incorrecta e incompleta.
Finalmente debe recordarse que antes de liberar un sistema de información es necesario entregar su documentación de referencia, ya sea en forma de manual de usuario, manual de administración, manual técnico para el mantenimiento del sistema, entre otros.
Limpieza de los datos
Los procesos de limpieza se implementan para: a) mejorar bases de datos que se encuentran en operación, b) fortalecer la integración de los datos provenientes de diferentes fuentes, c) mejorar procesos de migración de bases de datos, d) integrar datos provenientes de fuentes con bajo nivel de confiabilidad, entre otros. Ver la siguiente figura.
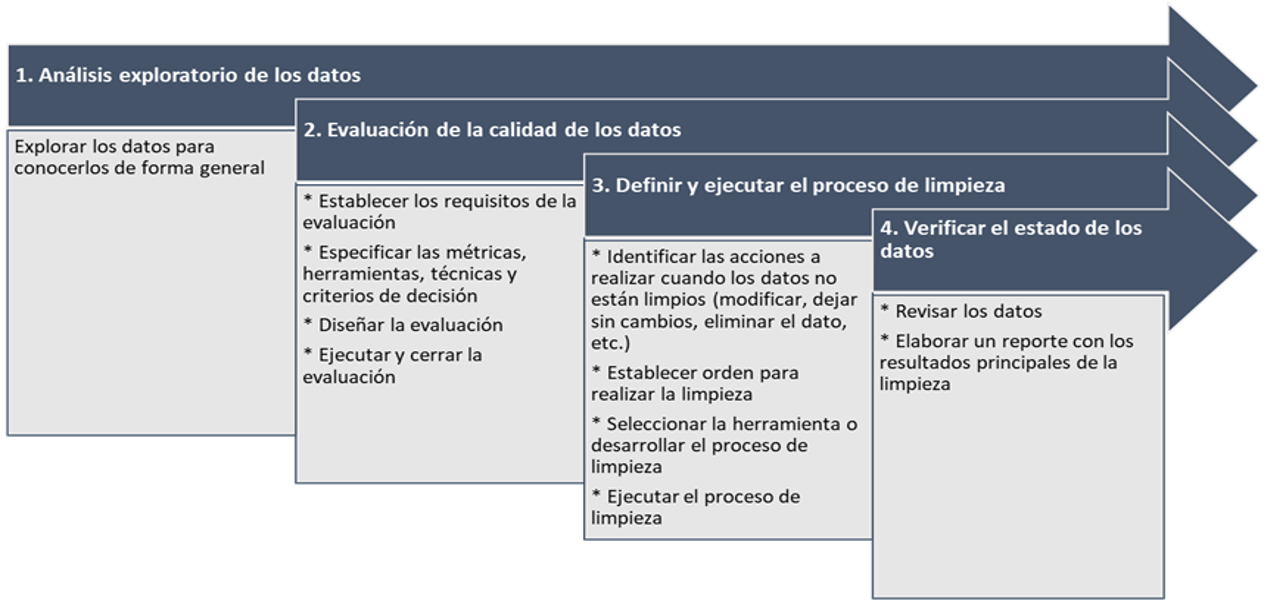
Proceso de limpieza de datos. Elaboración propia.
Con la finalidad de mejorar la calidad de los datos e incrementar el nivel de cumplimiento de los criterios establecidos, los procesos de limpieza de datos tendrán que ejecutar, al menos:
- Análisis exploratorio de los datos para conocer el estado actual de la información.
- Evaluación de la calidad de los datos acorde al estándar ISO/IEC 25040:2011 Systems and software engineering — Systems and software Quality Requirements and Evaluation (SQuaRE) — Evaluation process, con las siguientes actividades:
- Establecimiento de los requisitos de la evaluación. Definir el propósito de la evaluación, identificar los requisitos de calidad y las partes interesadas, los riesgos y el modelo de calidad a utilizar.
- Especificación de la evaluación. Se especifican las métricas, herramientas, técnicas y criterios de decisión.
- Diseño de la evaluación. Definir el plan y las actividades de la evaluación.
- Ejecución de la evaluación. Se ejecuta la evaluación obteniendo las métricas de calidad y se aplican los criterios de decisión.
- Cierre de la evaluación. Elaboración del “informe de resultados finales y conclusiones con base a los valores obtenidos” (Calabrese, 2019).
- Definir y ejecutar el proceso que se usará para limpiar los datos de acuerdo con los hallazgos encontrados.
- Verificar el estado de los datos después de realizar la limpieza y elaborar un informe de resultados que debe incluir las cifras del proceso:
- ¿Cuántos datos fueron modificados?
- ¿Cuántos datos fueron eliminados?
- ¿Cuántos datos necesitan limpieza manual?
- Entre otros.
Para que la limpieza se lleve a cabo es necesario transformar los datos que deben ser actualizados, de acuerdo con reglas establecidas para realizar el proceso. Algunas modificaciones pueden resolverse de forma sencilla mediante el reemplazo de valores o subcadenas o a través de cálculos sencillos para obtener un nuevo valor.
Algo más difícil es modificar valores de acuerdo con los catálogos establecidos, que deben ser revisados y aprobados antes del proceso de limpieza. Otras modificaciones pueden requerir de procesos aún más complejos e incluso sería necesario que algunas modificaciones se realicen de forma manual con la participación de expertos en los datos o mediante la comparación visual de documentos impresos.
Por otra parte, existen estrategias técnicas para detectar cuál es el mejor valor para permanecer en caso de inconsistencias o registros duplicados. De manera alternativa, de no contar con los elementos para implementar este tipo de estrategia, habría que documentar los elementos para determinar los datos que sean candidatos a eliminarse, cuando la inconsistencia de los datos no permitiera identificar el valor correcto de los mismos o se identifiquen valores incorrectos, por mencionar algunos casos.
Es importante considerar diversas causas que pueden ensuciar los datos. Algunas de ellas se pueden prevenir, por lo que es recomendable hacer un análisis de riesgos con la finalidad de identificar acciones para mitigar el impacto y fortalecer la calidad de los datos. Estas son algunas de las causas que pueden provocar la limpieza de los datos.
- En los sistemas informáticos se presenta alguna de estas situaciones:
- Validaciones insuficientes, es decir, el sistema no cuenta con validaciones de los datos que son ingresados o las validaciones son insuficientes.
- El sistema cuenta con validaciones, pero no funcionan adecuadamente.
- Errores de captura de información: sintaxis no adecuada, errores ortográficos, entre otros.
- Modificación directa en la base de datos sin considerar las reglas de validación de los sistemas informáticos por personal con acceso y privilegios suficientes.
- Intrusión y modificación en las bases de datos por personal no autorizado.
- Definición escasa o inexistente sobre los dominios de datos.
- Definición insuficiente o inexistente sobre las restricciones de integridad, llave primaria, unicidad y verificación (check) en las bases de datos.
- Carga de datos incorrecta.
- Errores de diseño en la base de datos o en los sistemas.
- Datos calculados de forma errónea.
- Incumplimiento de reglas de negocio.
- Diferentes medios de ingreso de información y fuentes de datos inconsistentes.
Se recomienda aprender de los hallazgos identificados de manera proactiva para detectar las oportunidades de mejora y atender de forma directa la causa raíz que ocasiona los problemas descritos anteriormente. De esta forma, la próxima vez los datos estarán más limpios y serán de mejor calidad para apoyar los fines de la institución.
Esto implica una reingeniería. Es decir, aquellas reglas de negocio, omisiones o errores en la captura, producción, mantenimiento o archivado detectadas en el perfilado de datos y ejecutados en la limpieza, ahora deberán implantarse en el sistema original a fin de que se establezca una solución efectiva y evitar que el enfoque se centre en la limpieza de los datos.
Migración de datos
Las migraciones de datos consisten en realizar un proceso de extracción, transformación y carga (ETL, por sus siglas en inglés) con la finalidad de desplazar datos de uno o varios orígenes hacia un nuevo destino. Por ejemplo: a) de un sistema de almacenamiento de datos a otro, b) de un formato de datos a otro o c) entre diferentes sistemas informáticos.
Los proyectos de migración de datos enfrentan varios retos, uno de ellos es la mala calidad de los datos, debido a que “es una de las razones por las que fracasan los proyectos de migración de datos, ya que estos proyectos implican el movimiento de grandes volúmenes de datos en formatos dispares” (Iqbal, 2019). Una inapropiada estrategia y/o planeación puede conllevar a datos inexactos que contengan redundancias y valores desconocidos, a la pérdida de datos o, en su caso, a la superación de fechas o presupuestos.
“Según Gartner, la mala calidad de los datos puede tener un impacto financiero promedio de $10,8 millones de dólares por año (2020). Además, los datos incorrectos significan que se está procesando información incorrecta, lo que podría implicar un nuevo trabajo” (Iqbal, 2019).
Entre los factores a considerar dentro de un proyecto de migración de datos están (Power Data, 2020):
- Tiempo que llevará realizar la migración completa.
- Tiempo de inactividad necesaria para realizar la migración de datos y reiniciar la operación.
- Riesgo derivado de problemas técnicos de compatibilidad, corrupción de datos, problemas de rendimiento de aplicaciones y pérdida u omisión de datos, entre otros.
Entre las estrategias de migración de los datos se encuentran:
- Migraciones en big bang. Implica realizar toda la migración dentro de una pequeña ventana de tiempo definida. Los sistemas conectados quedan inactivos mientras se someten los datos a procesos de ETL y se trasladan a la nueva base de datos.
- Esta estrategia conlleva riesgos, por lo que existe una intensa presión sobre la migración.
- La verificación y aprobación de datos se encuentran en la ruta crítica.
- Migraciones incrementales. Implica la ejecución de los sistemas antiguos y nuevos en paralelo, lo que evita la inactividad y las interrupciones operativas que requieren las aplicaciones de misión crítica que operan 24/7.
- La migración se realiza por fases y agrega cierta complejidad al diseño, pues debe ser posible rastrear qué datos se han migrado y qué datos no para redireccionar las peticiones cuando los sistemas operan en paralelo.
Para minimizar los riesgos relacionados con la migración de los datos, es necesario considerar lo siguiente:
- Entender qué datos se están migrando, de qué tipo son, cuál es su origen y qué formato adquirirán en destino, una vez completado el traslado.
- Establecer metadatos o un diccionario de datos que, además del tipo de dato, origen, formato, entre otros elementos, describa cuál será la información almacenada en ese dato y la unidad de medida. La semántica del dato debe ser clara para determinar qué hacer en la transformación del dato.
- ¿Qué pasa cuando se migran dos sistemas informáticos a uno solo? Se debe hacer correspondencia y mapeo de esquemas. También será necesario resolver los problemas de heterogeneidad, sintáctica y semántica antes de transformar los datos al modelo que contendrá los datos de las dos fuentes.
- Considerar una metodología o procedimiento para el movimiento de los datos, que haya funcionado anteriormente o en áreas con necesidades semejantes.
- Definir lo que es viable y lo que no, en función de lo que las fuentes de datos admiten y lo que es razonable.
- Hacer una copia de seguridad de los datos antes de la ejecución de la migración.
- Deben definirse reglas de calidad de los datos para identificar y corregir cualquier error antes de llevar a cabo la migración.
- Una vez identificada cualquier posible incidencia con sus datos de origen, se debe proceder a la limpieza de los mismos.
- Preferentemente, aplicar los procesos ETL antes de proceder a la migración, como mínimo se deben considerar las etapas de transformación y carga.
- Definir e implementar políticas de migración de datos para garantizar el orden necesario a lo largo del proceso.
- Apostar por las pruebas y validación de los datos migrados, por ser una manera efectiva de asegurar que reúnen todos los atributos de calidad necesarios.
- El proceso de pruebas permite identificar mejoras en el proceso de migración y en los datos. Además contribuye a detallar la estimación del tiempo necesario para migrar, debido a que en algunas ocasiones podría ser más complejo de lo esperado.
Se puede hacer uso de herramientas para apoyar la migración de los datos, ya sea que se construyan (lo que implica destinar recursos humanos y tiempo para desarrollarlas) o, en su caso, se utilicen las desarrolladas por terceros o aquellas de tipo comercial. Un ejemplo son las herramientas ETL, adecuadas para migrar datos de una base de datos a otra, principalmente en proyectos que presentan pocas conexiones entre origen y destino.
Calidad de datos abiertos
Los datos que las áreas universitarias identifiquen como abiertos pueden ser reutilizados y puestos a disposición de la sociedad, de acuerdo con las políticas de compartición que establezcan. Para mejorar la calidad de los datos abiertos se pueden seguir las pautas siguientes:
- Usar alternativas de búsqueda adicionales a los buscadores excesivamente guiados o acotados.
- Verificar que los datos no estén incompletos, demasiado limitados por el periodo de tiempo, por la frecuencia de la publicación o con información muy básica que “aporta poco valor y no cumple con los mínimos necesarios para obtener una representación completa” (Gobierno de España, 2017), es decir, que aporten el nivel de detalle adecuado.
- Verificar que los datos sean de fácil acceso.
- Corroborar que los datos estén actualizados y no sean obsoletos.
- Confirmar que los formatos usados sean reutilizables y estandarizados.
- Establecer claramente las licencias y condiciones de reutilización de los datos.
- Revisar la conformidad con la normatividad vigente.
- Evaluar la calidad de los datos de forma periódica.
- Generar metadatos que faciliten la reutilización de los datos abiertos.
Indicadores de actividad y desempeño
Una tarea relevante de la gestión académica administrativa es dar seguimiento y evaluar de manera clara y objetiva los procesos y resultados de las acciones institucionales emprendidas. Al contar con información estadística confiable es posible construir indicadores de actividad o desempeño para describir y valorar a la institución o a una entidad académica en particular.
Para el titular de una facultad o escuela y su equipo de trabajo es importante conocer tanto el curso de las acciones emprendidas como los resultados obtenidos, así como tomar decisiones respecto a la continuidad o no de los proyectos, su fortalecimiento o modificación, si así fuera el caso.
En este sentido el indicador es crucial porque es uno de los elementos que nos dará la pauta del grado de cumplimiento. Desde hace décadas, es frecuente encontrar en diversos estudios y reportes institucionales indicadores de actividad (descriptivos) “tales como la magnitud de la demanda, de la población escolar, el egreso, la titulación, el número de proyectos de investigación, el número y tipo de productos de investigación, la cantidad de asistentes a las actividades de difusión y extensión”, por mencionar algunos (DGPL, 2021: I).
También se han utilizado extensamente indicadores de desempeño (valorativos), tales como eficiencia terminal (porcentaje de alumnos egresados de una generación determinada), costo promedio por alumno, regularidad (porcentaje de alumnos regulares de una generación o de la totalidad de alumnos inscritos), relaciones demanda/cupo, índices de aprobación/reprobación, libros o artículos publicados por investigador, variaciones de asistencia a actividades de difusión o extensión, entre otros (DGPL, 2021:I).
“La información obtenida a partir de indicadores de desempeño permite, asimismo, que las entidades (o la institución en su conjunto) puedan compararse entre sí o con otras instituciones; impulsar procesos de innovación educativa o académica; distribuir los recursos conforme a prioridades y rendir cuentas tanto a las propias comunidades como a instituciones públicas, organismos internacionales y, en general, a la sociedad en su conjunto” (DGPL, 2021:I).
La información confiable y comparable
“En el ámbito de las instituciones de educación superior existe un consenso en cuanto a los conceptos de relevancia estadística más utilizados para conocer y valorar su desempeño. Sin embargo, para que esta estadística adquiera la categoría de confiable y comparable se debe cuidar la especificación clara de lo siguiente” (CGPL, 2022:16) (Ver ejemplo en el Anexo 3):
- Los conceptos principales de interés estadístico.
- El establecimiento de las fechas de corte adecuadas para la generación y difusión de la información estadística institucional.
- La documentación de los criterios estadísticos para el tratamiento de los datos.
- La descripción de los contenidos, formatos o las dimensiones asociadas a los conceptos de interés (niveles de agregación o subgrupos y categorías) (CGPL, 2022:16).
El flujo sistemático de la información
“Las solicitudes formales de información a las fuentes primarias contienen guías técnicas en donde se describen los acuerdos sobre los conceptos y criterios que conforman la estadística institucional. Incluyen los protocolos de transferencia y demás aspectos técnicos que deben documentarse para asegurar su flujo sistemático” (CGPL, 2022:16). Las más de 150 entidades académicas y dependencias administrativas universitarias son potencialmente fuentes primarias de información.
“Conviene diferenciar dos tipos de fuentes de información: las fuentes primarias que son el origen de las estadísticas relevantes y las fuentes responsables que les otorgan valor estadístico a las variables mediante algún proceso de homologación o normalización. En ocasiones una fuente primaria es también una fuente responsable, sin embargo, puede no ser así, sobre todo si las fuentes primarias tienen objetivos de gestión distintos al interés estadístico institucional. En la administración central universitaria se tienen relevantes sistemas de gestión que se convierten en fuentes primarias de gran valor para resolver el flujo de información” (CGPL, 2022:17).
Métricas de calidad de los indicadores
Las métricas de calidad de los indicadores se describen en una ficha o documentación técnica que contiene lo siguiente (ver ejemplo en el Anexo 3):
- Nombre del indicador
- Definición conceptual
- Unidad de medida
- Fórmula de cálculo (para indicadores de desempeño, como son la regularidad o la eficiencia terminal)
- Interpretación (indicadores de desempeño)
- Utilidad/fin/propósito
- Niveles de desagregación o subconjuntos posibles
- Categorías posibles/útiles
- Fuentes de información (primaria y responsable)
- Criterio estadístico o método de cálculo
- Periodicidad de medición
- Fecha de corte sugerida
- Observaciones
Se generarían tantas fichas técnicas para un mismo concepto como modalidades de cálculo y finalidades del indicador existan.
Anexo 1. Descripción de los atributos de calidad de los datos
El estándar ISO 25012:2008 Software engineering — Software product Quality Requirements and Evaluation (SQuaRE) — Data quality model presenta quince características de calidad que pueden ser abordadas desde los puntos de vista dependiente e inherente del sistema. Las características dependientes son aquellas cuya calidad está subordinada al sistema que hace uso de los datos.
Características dependientes según ISO /IEC 25012:2008
|
Dimensión |
Descripción |
|
Disponibilidad (Availability) |
El grado en el cual el dato tiene atributos que le permiten ser recuperados por usuarios autorizados o por aplicaciones en un contexto específico de uso. |
|
Portabilidad (Portability) |
El grado en el cual el dato tiene los atributos que le permiten ser instalado, sustituido o movido de un sistema a otro conservando la calidad existente en un contexto específico de uso. |
|
Recuperabilidad (Recoverability) |
El grado en el cual el dato puede mantener y conservar un nivel especificado de operaciones y calidad, aún en caso de falla. |
(Pinzón, 2013:115)
Las características inherentes se refieren al “grado con el que las características de calidad de los datos tienen el potencial intrínseco para satisfacer las necesidades establecidas cuando los datos son utilizados bajo condiciones específicas” (ISO 25000, 2008).
Características inherentes según ISO /IEC 25012:2008
|
Dimensión |
Descripción |
|
Exactitud (Accuracy) |
El grado en el cual el dato tiene atributos que representan correctamente el valor del atributo intencionado de un concepto o evento en un contexto específico de empleo. |
|
Completitud (Completeness) |
El grado al cual el dato del sujeto asociado con una entidad tiene valores para todos los atributos esperados e instancias de entidad relacionadas en un contexto específico de uso. |
|
Consistencia (Consistency) |
El grado en el cual el dato tiene los atributos que son libres de contradicción y son coherentes con otros datos en un contexto específico de uso. |
|
Credibilidad (Credibility) |
El grado en el cual el dato tiene atributos que son considerados verdaderos y creíbles por usuarios en un contexto específico de uso. |
|
Actualidad (Currentness) |
El grado en el cual el dato tiene los atributos que son del período correcto en un contexto específico de uso. |
(Pinzón, 2013:116)
Existen características que son comunes tanto al enfoque inherente como al dependiente, las cuales se presentan en la siguiente tabla.
Características compartidas (inherentes y dependientes) según ISO /IEC 25012:2008
|
Dimensión |
Descripción |
|
Accesibilidad (Accessibility) |
El grado en el cual el dato puede ser accedido en un contexto específico de uso, en particular, por personas en situación de discapacidad que necesitan el soporte de tecnología o una configuración especial. |
|
Cumplimiento / Conformidad (Compliance) |
El grado en el cual el dato tiene atributos que se adhieren a normas, convenciones o regulaciones vigentes y reglas similares relacionadas con la calidad de datos en un contexto específico de uso. |
|
Confidencialidad (Confidentiality) |
El grado en el cual el dato tiene los atributos que aseguran que sólo es accesible e interpretable por usuarios autorizados en un contexto específico de uso. El nivel de privacidad indica si se trata de datos de carácter público o privado, con esto se pueden discernir los distintos manejos de la información desde sus metadatos. |
|
Eficiencia (Efficiency) |
El grado en el cual el dato tiene los atributos que pueden ser procesados, y proporciona los niveles esperados de funcionamiento (desempeño) usando las cantidades y los tipos de recursos apropiados en un contexto específico de uso. |
|
Precisión (Precision) |
El grado en el cual el dato tiene atributos que son exactos o que proporcionan la discriminación en un contexto específico de uso. |
|
Trazabilidad (Traceability) |
El grado en el cual el dato tiene atributos que proporcionan un rastro de auditoría de acceso a los datos y de cualquier cambio hecho a los datos en un contexto específico de uso. |
|
Entendimiento (Understandability) |
El grado en el cual el dato tiene atributos que le permiten ser leído e interpretado por usuarios, y es expresado en lenguajes apropiados, símbolos y unidades en un contexto específico de uso. |
Anexo 2. Métricas de acuerdo con el estándar ISO/IEC 25024:2015
|
Característica |
Métrica |
|
Exactitud |
Exactitud sintáctica de los datos |
|
Exactitud semántica de los datos |
|
|
Aseguramiento de la exactitud de los datos |
|
|
Riesgo de inexactitud de un conjunto de datos |
|
|
Exactitud del modelo de datos |
|
|
Exactitud de los metadatos |
|
|
Rango de la exactitud de los datos |
|
|
Completitud |
Completitud de registros |
|
Completitud de atributos |
|
|
Completitud de archivos de datos |
|
|
Completitud de valores de datos |
|
|
Registros vacíos en un archivo de datos |
|
|
Completitud del modelo de datos conceptual |
|
|
Completitud de los atributos del modelo de datos conceptual |
|
|
Completitud de los metadatos |
|
|
Consistencia |
Integridad referencial |
|
Consistencia del formato de datos |
|
|
Riesgo de inconsistencia de datos |
|
|
Consistencia de la arquitectura |
|
|
Cobertura de la consistencia de valores de datos |
|
|
Consistencia semántica |
|
|
Credibilidad |
Credibilidad de los valores |
|
Credibilidad de la fuente |
|
|
Credibilidad del diccionario de datos |
|
|
Credibilidad del modelo de datos |
|
|
Actualidad |
Frecuencia de actualización |
|
Oportunidad de la actualización |
|
|
Requisito de actualización de los elementos (ítems) |
|
|
Accesibilidad |
Accesibilidad de usuario |
|
Accesibilidad de dispositivos |
|
|
Accesibilidad del formato de datos |
|
|
Conformidad |
Conformidad regulatoria de los valores y/o formato de datos |
|
Conformidad regulatoria debido a la tecnología |
|
|
Confidencialidad |
Uso de cifrado |
|
No vulnerabilidad |
|
|
Eficiencia |
Formato de los elementos (ítems) de datos eficiente |
|
Eficiencia usable |
|
|
Eficiencia en formato de datos |
|
|
Eficiencia en procesamiento de datos |
|
|
Riesgo de espacio desperdiciado |
|
|
Espacio ocupado por duplicación de registros |
|
|
Desfase temporal de actualización de datos |
|
|
Precisión |
Precisión de valores de datos |
|
Precisión del formato de datos |
|
|
Trazabilidad |
Trazabilidad de valores de datos inherentes |
|
Trazabilidad del acceso a los datos |
|
|
Trazabilidad de valores de datos dependientes del sistema |
|
|
Entendibilidad |
Entendibilidad de símbolos |
|
Entendibilidad semántica |
|
|
Entendibilidad de datos maestros |
|
|
Entendibilidad de valores de datos |
|
|
Entendibilidad del modelo de datos |
|
|
Entendibilidad de la representación de datos |
|
|
Entendibilidad de datos maestros enlazados |
|
|
Disponibilidad |
Tasa de disponibilidad de datos |
|
Probabilidad de datos disponibles |
|
|
Disponibilidad de elementos de arquitectura |
|
|
Portabilidad |
Ratio de portabilidad de datos |
|
Portabilidad de datos prospectivos |
|
|
Portabilidad de elementos de arquitectura |
|
|
Recuperabilidad |
Tasa de recuperabilidad de datos |
|
Respaldo de seguridad (Backup) periódico |
|
|
Recuperabilidad de la arquitectura |
Métricas de la ISO/IEC 25024 (Adaptado de Fernández, 2018)
Anexo 3. Ejemplos de fichas técnicas de indicadores de actividad y desempeño




Citas
1. Un modelo de datos físico es un modelo específico de bases de datos que representa objetos de datos relacionales (por ejemplo: tablas, columnas, claves principales y claves externas) y sus relaciones. Un modelo de datos físico se puede utilizar para generar sentencias DDL que después se pueden desplegar en un servidor de base de datos (IBM, 2021).
2. La normalización es el proceso que asigna atributos a entidades en forma tal que la redundancia de datos disminuye o desaparece. Se realiza para evitar redundancias, inconsistencias y anomalías lógicas, así como para proteger la integridad de los datos.
3. https://eaminds.com/2018/08/03/modelando-nosql-data-bases/
4. https://www.mongodb.com/docs/manual/core/data-modeling-introduction/
Referencias
- Calabrese (2019). Guía para evaluar calidad de datos basada en ISO/IEC 25012. Revisado el 26 de octubre de 2021. Disponible en: https://core.ac.uk/download/pdf/301104068.pdf
- DAMA International (2017). DAMA-DMBOK: Data Management Body of Knowledge (2nd Edition). Basking Ridge.
- Fernández (2018). Desarrollo de un modelo de calidad de datos aplicado a una solución de inteligencia de negocios en una institución educativa: caso lambda. Tesis para el Título de Ingeniero Informático. Pontificia Universidad Católica del Perú. Disponible en: https://tesis.pucp.edu.pe/repositorio/bitstream/handle/20.500.12404/12014/FERNANDEZ_MARSHALL_CALIDAD_INTELIGENCIA_NEGOCIOS.pdf?sequence=1
- Gartner (s.f.). Gartner Glossary. Dark Data. Revisado el 26 de octubre de 2021.
https://www.gartner.com/en/information-technology/glossary/dark-data - Gobierno de España (2017). Manual práctico para mejorar la calidad de los datos abiertos. Revisado el 25 de octubre de 2021. Disponible en:
https://datos.gob.es/sites/default/files/doc/file/manual_practico_para_mejorar_la_calidad_de_los_datos_abiertos_1_0.pdf - González (2013). Aplicación del estándar ISO/IEC 9126-3 en el modelo de datos conceptual entidad-relación. Revista Facultad de Ingeniería, UPTC, julio - diciembre de 2013, Vol. 22, No. 35. Revisado el 7 de octubre de 2021.Disponible en:
http://www.scielo.org.co/pdf/rfing/v22n35/v22n35a10.pdf - IBM (2021). Modelos físicos de datos. Revisado el 11 de noviembre de 2022. Disponible en:
https://www.ibm.com/docs/es/radfws/9.6?topic=SSRTLW_9.6.0/com.ibm.datatools.core.ui.doc/topics/cphysmod.htm - Iqbal (2019). Gestión de la calidad de los datos: ¿qué es y por qué es importante? Revisado el 26 de octubre de 2021.
https://www.astera.com/es/type/blog/data-quality-management/ - ISO 25000 (2008). ISO/IEC 25012. Revisado el 7 de octubre de 2021. Disponible en: https://iso25000.com/index.php/normas-iso-25000/iso-25012
- Martínez (2017). Malas Prácticas en el Diseño de la Base de Datos: ¿Estás cometiendo estos errores? Revisado el 29 de octubre de 2021. Disponible en:
https://www.toptal.com/database/malas-practicas-en-el-diseno-de-la-base-de-datos-estas-cometiendo-estos-errores - Jacintogr (2020). La importancia de la calidad de los datos en las empresas. Revisado el 29 de octubre de 2021. Disponible en:
https://itblogsogeti.com/2020/11/25/la-importancia-de-la-calidad-de-los-datos-en-las-empresas/ - Yanes (2019). La evaluación de la calidad de datos: una aproximación criptográfica. Computación y Sistemas, Vol. 23, No. 2, 2019, pp. 557–568 doi: 10.13053/CyS-23-2-2899. Disponible en: http://www.scielo.org.mx/pdf/cys/v23n2/1405-5546-cys-23-02-557.pdf
- Power Data (2020). Migración de datos: definición, desafíos y mejores prácticas para afrontarla. Revisado el 3 de noviembre de 2021. Disponible en:
https://www.powerdata.es/migracion-de-datos - Dirección General de Planeación (DGPL), (2021). Indicadores de desempeño para escuelas y facultades de educación superior de la UNAM. UNAM, UNAM. Revisado el 10 de abril de 2023. Disponible en:
https://www.planeacion.unam.mx/Planeacion/Apoyo/IndDesFyE_nov2021.pdf - Coordinación General de Planeación y Simplificación de la Gestión Institucional (CGPL), (2022). Un modelo de planeación y los sistemas de información para la toma de decisiones en una organización compleja. UNAM. Revisado el 10 de abril de 2023. Disponible en:
https://www.planeacion.unam.mx/Planeacion/Apoyo/UNAM-modeloplan-cgpl.pdf
Créditos
Elaboración
Susana Laura Corona Correa (DGTIC)
Alberto González Guízar (DGTIC)
Jaime Escamilla Rivera (CGPL)
Revisión
María del Pilar Angeles (IIMAS)
Hugo Alonso Reyes Herrera (DGTIC)
Leticia Martínez Calixto (DGTIC)
Fernando Israel González Trejo (FES Acatlán)
Armando Vega (DGAE)
Leonard Pulido Cauzard (DGAE)
Ana Pérez Arteaga (IIMAS), Fernando Zaragoza Hernández (DGAE)
Rogelio Palma Rodríguez (DGPo)
José Gerardo Moreno Salinas (CUAIEED)
Alejandra Fonseca Salazar (COUS)
Alejandro Bosch Maldonado (DGACO)
Marcela Juliana Peñaloza Báez (DGTIC)
Luz María Castañeda de León (DGTIC)
Revisor de estilo: José Luis Olguín Martínez (DGTIC).